
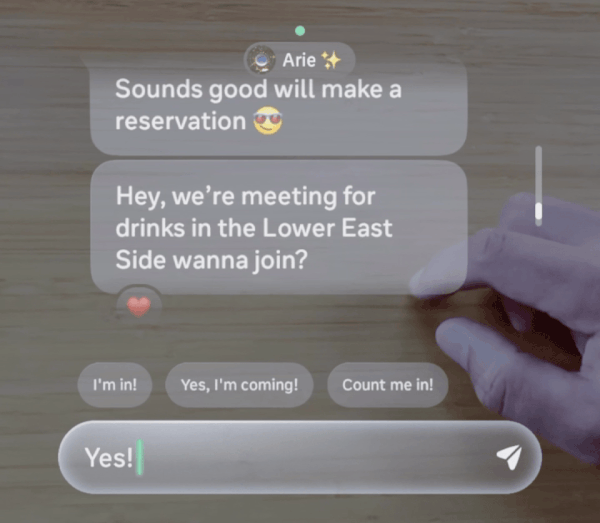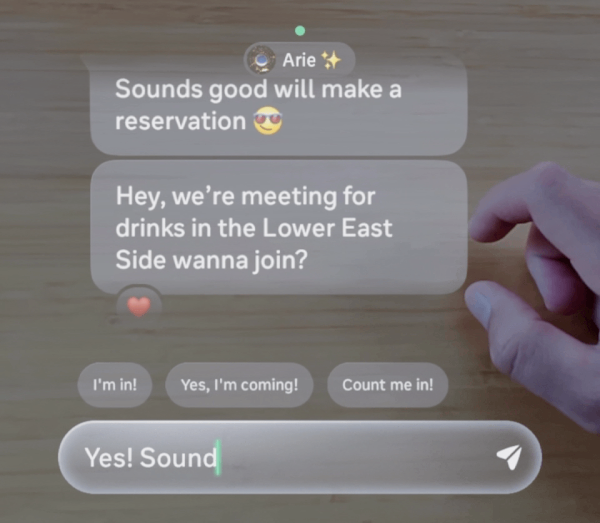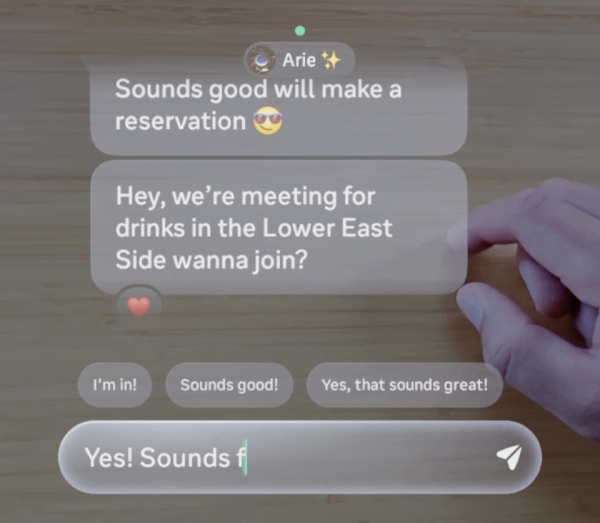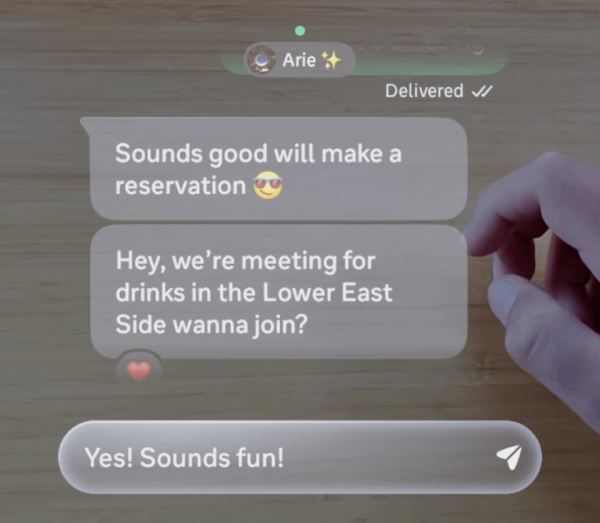
The team could not call AI handwriting ready until it could explain what was actually failing.
The feature had a clear ambiguity problem. A visible decoding failure could come from the model, the sensor, the protocol design, or the interaction itself. Without a way to tell those apart, no one could agree on what to fix or whether the feature was close to ready.
The Meta Neural Band uses EMG to detect wrist muscle signals and decode them as gesture-based input. Handwriting is one of the most complex interactions it supports, and the model trained on session data: every session had direct consequences for what it learned.
When a character was misread or a gesture went unrecognized, the cause was not obvious. The signal could be noisy. Sensor placement could have drifted. The task wording could have created ambiguity. Or the interaction design could be asking for a gesture pattern people did not naturally produce. Treating those failures as interchangeable sent teams in the wrong direction.

The system was under active development. Model updates, firmware changes, and prototype iterations overlapped with testing, requiring a protocol flexible enough to keep up without losing consistency across sessions.
Which failures were ready for product action, which pointed to model or sensor work, and which required a cleaner evidence standard before anyone could make a readiness call.
Failing to attribute failures correctly would cost iteration cycles and introduce noise into the model the team was trying to improve.
The model was accumulating training data continuously, which meant two things depended on getting it right: the product readiness decision, and what the model would become.
Every session that passed QA fed the model. Every session that failed silently introduced noise that would shape model behavior for future users. The difference was whether the team had defined what valid data looked like.
Calling the feature ready without knowing which failures were fixable, and by which team, risked shipping prematurely or blocking work that was already done. On a fast-moving R&D program with short iteration cycles, both were costly.
Participant intake and wrist measurement, EMG calibration and signal quality checks at session start, real-time protocol adaptation, end-of-day QA, and cross-functional reporting to research scientists and engineers.
Sixteen participants per day across two daily sessions. Every decision about what counted as valid data compounded forward into the training pipeline.
I separated what the system did from what participants did, and used RITE to act on findings before the next session started.
Attribution before action: establish a failure taxonomy first, then let RITE drive rapid adjustment within each category. A recognition score alone could not tell the team who needed to act or what needed to change.
-
01
RITE (Rapid Iterative Testing and Evaluation)
Protocol and configuration adapted between sessions based on observed failures. Changes could roll into the next session without waiting for a formal review cycle.
-
02
Behavioral Observation
Daily in-lab sessions tracked how participants produced handwriting input and how natural variation affected recognition. The goal was to distinguish what participants were doing from what the system was doing, without directing them to change how they wrote.
-
03
Software Validation
New builds and firmware updates were validated with Python-based signal checks before participants arrived. Catching issues pre-session prevented compromised data from entering the training pipeline undetected.
-
04
Data QA
Daily quality checks flagged missing data, signal anomalies, and protocol deviations. Explicit criteria defined what made a session valid for model training, creating a consistent standard across a long-running, multi-study program.
Three patterns in early data produced decisions that changed how the rest of the program ran.
The clearest findings were not about failure rates. They were about which assumptions were wrong and what needed to change before the evidence could be trusted.
-
01
Sensor placement and calibration appeared to drive early failures, not participant behavior.
Session QA logs from the first weeks showed elevated gesture recognition failures that did not correlate with participant behavior. The pattern pointed toward sensor positioning, which became the basis for moving recalibration to a required session-start step rather than an as-needed intervention.
-
02
Loose handwriting was the target population, not a quality problem.
Session reviews consistently showed participants who wrote loosely or inconsistently were producing exactly the data the model needed. Coaching them toward neater writing would have biased the training set and undermined the model's ability to handle real-world variation.
-
03
Attributable failures traced more often to model or sensor limits than to the interaction design.
Documented failure patterns pointed more often to model classification limits or sensor signal quality than to the interaction design. That distinction changed where engineering attention needed to focus.
-
04
Concurrent studies created data contamination risk without explicit routing.
When participant pools overlapped across concurrent studies, session data could not be cleanly attributed to a single protocol. Without explicit routing, contaminated data would have been indistinguishable from clean data, making the validity standard unenforceable.
Define session validity around setup quality, not handwriting style, and route each failure type to the team that could act on it.
The recommendations were not about changing the feature. They were about changing what the team was measuring and how it attributed what it found.
-
01
Formalize sensor recalibration as session-start protocol.
Move calibration from an ad hoc fix to a required step before any participant task begins. Consistency at setup was the precondition for interpretable gesture data.
-
02
Build QA standards around session setup, not participant behavior.
Valid data meant clean signal, correct sensor placement, confirmed task comprehension, and an intact protocol. Not controlled handwriting. Participants who wrote naturally were producing exactly what the model needed.
-
03
Attribute failures explicitly and document the reasoning.
Each ambiguous session received a documented classification: model issue, sensor issue, protocol issue, or design issue. Uncertain cases escalated to research science review rather than defaulting to pass/fail.
-
04
Separate concurrent study protocols and data streams from the start.
Participant routing, data labeling, and protocol tracking needed to be distinct across studies running in parallel. Retrofitting those boundaries mid-program was expensive. Building them in at study launch was not.
Decision Impact
Before: failures with no direction and sessions with no standard for validity. After: a failure framework and QA criteria the model and product teams could act on.
- Failure framework
- A classification system separating model, sensor, protocol, and design failures, with documented reasoning and a defined escalation path for edge cases
- Training data standard
- QA criteria established with research scientists that defined valid sessions for model training, applied across a multi-study program running in parallel
- Publication
- Data contributed to foundational sEMG research and a peer-reviewed Nature publication on neuromotor interfaces
Failures stopped competing for priority without evidence. The model and product teams had a shared standard for what the data could support and a clear path for what each failure type required next.
At this scale, protocol decisions and data quality decisions are the same decision.
If the model learns from participants, the protocol cannot correct what it is supposed to learn.
The instinct to standardize handwriting was reasonable. It was also exactly wrong. The model needed natural variation, not idealized behavior.
RITE at this volume is a coordination problem, not just a research method.
Adjusting protocol between sessions required same-day alignment across engineering, research science, and program management. The iteration loop only worked because the team had a clear path for turning findings into same-day decisions. Without that infrastructure, findings arrived faster than anyone could act on them.
Defining valid matters more than scoring failure.
The most useful output was not a gesture recognition pass rate. It was a precise definition of what made a session valid for model training. That gave the model team something to act on and the research team a standard it could defend.